Song-Genre-Classification
Group 48 Project
Introduction/Background
Literature Review
Music information retrieval, or MIR, is a growing science where datasets are used to extract musical information from songs or other forms of music. [9] There has been a growing interest in utilizing song lyrics as a valuable source of information for genre classification. Existing studies have explored various methods, such as natural language processing and statistical models, to extract meaningful features from lyrics and predict musical genres accurately [10].
Dataset
The dataset’s information comes from Genius which is a platform that contains content including songs, poems and books, but mostly songs. Each entry in the dataset represents a piece of content from Genius and includes various features such as title, genre, artist, year, views, artist features, lyrics, ID, and language. The dataset was changed from what we picked originally in our proposal due to this dataset having the genre information associated with each song and the data being more informative.
Dataset Link: https://www.kaggle.com/datasets/carlosgdcj/genius-song-lyrics-with-language-information
Problem Definition
Problem
Our objective is to develop a machine learning model capable of accurately predicting the genre of a song from its lyrics. This process involves: determining a set of appropriate music genres, converting song lyrics into usable data, and classifying lyrics into distinct musical genres by leveraging patterns extracted from the content of lyrics.
Motivation
Our motivation is to contribute to the scope of streaming platforms and other services. Automated genre classification is crucial to the function of platforms and recommendations systems. By making a model that can place songs into genres without platform manager intervention, the user experience on streaming platforms may be enhanced. Further, classifying the lyric-genre could provide insights into cultural traditions and the evolving trends within different music genres.
Methods
The three data preprocessing methods we plan on utilizing are feature extraction, feature selection, and data splitting. Feature extraction will allow us to process the raw lyric data into underlying patterns found between lyrics and genres. Feature selection will enable us to pick out the most relevant features to focus on. Data splitting will allow us to split our data into a train set and a test set [3]. The ML algorithms and supervised learning methods we plan to use are Support Vector Machine Classification, Decision Tree Classification, and Multinomial Naive Bayes. These methods are useful in classifying the features found into categories based on different parameters [1, 2]. For example, Multinomial Naive Bayes will be useful in predicting the genre based on the frequency of certain words [2]. All of these methods can be found in the scikit-learn library.
Midterm Progress:
The three data preprocessing methods we implemented were encoding each of the genres into numbers, feature extraction, and splitting our dataset into a train and a test set. In order to encode each of the genres into numerical values, we used scikit-learn’s implementation of Ordinal Encoder. We decided to encode our genres because they were originally all strings, but as numbers it will be easier to compare our predicted labels from our trained models against the true labels when measuring the accuracy of our models. Another preprocessing method we implemented was feature extraction. Since lyrics can have numbers, special characters, and insignificant words such as “the”, “is”, “of”, etc., we decided to get rid of these words in our lyrics dataset, extracting only the essential words of the lyrics to train our models with. Lastly, we split our dataset into a training dataset and a test dataset with 80% of our dataset being used for training and 20% of it being used for testing. Since we are implementing supervised learning ML algorithms, it is important to split the data so we can train the model with the train set and see if it accurately predicts the true labels of the test set.
The ML algorithm we implemented was the Multinomial Naive Bayes model. We chose this model because it is a supervised learning algorithm that excels in text classification, which aligns well with our project’s goal of genre classification based on lyrics (text). More specifically, MNB uses the frequency of words to determine classifications, which is particularly helpful for genre classification given lyrics. This is because certain words or phrases tend to be more prominent in specific genres, so the frequency of words in lyrics can be a good indicator to predict the genre. We also chose MND because it allows for interpretability, so we can see which words or features contributed the most to the classification and understand why a song is classified into a specific genre.
Final Progress:
The 2 additional ML algorithms that were implemented were Support Vector Machine Classification and Decision Tree Classification. Support Vector Machine is a powerful supervised learning algorithm used for classification tasks. SVM was chosen because of its ability to handle non-linear data which is very likely in our dataset because two or more genres may have similar patterns/words that distinguish them. SVM is able to pick out these complex patterns in each song lyric and classify them. In our project, SVM is employed to classify song lyrics into distinct musical genres based on patterns extracted from the content of the lyrics. Decision Tree Classification is another popular supervised learning algorithm used for classification tasks. In our project, song lyrics are transformed into numerical feature vectors using techniques like TF-IDF vectorization, converting raw text data into a suitable format for training. Decision Tree Classfication is useful for this type of data because it can handle numerical features, it is also very good with classifying non-linear data, and it is robust to irrelevant features. Although preprocessing was done to remove any English stop words from the dataset, there is still a lot of trivial features within the lyrics and decision trees are able to focus on the most important features regardless of the other features.
Results/Discussion
We plan on using 4 quantitative metrics. The first metric is accuracy [4,5]. The second metric is precision [4,6]. The third metric is recall [4,7]. The last metric is the F1 score [4,8]. The goal for all would be to maximize the value as close to 1 as possible, but a value of .8 or above can be considered successful for accuracy and values above .7 for each genre can be considered successful for precision, recall and F1 score [5,6,7,8]. We expect to get an accuracy score above .8 and precision, recall and F1 scores above .7 for each class.
Final Results:
Confusion Matrices
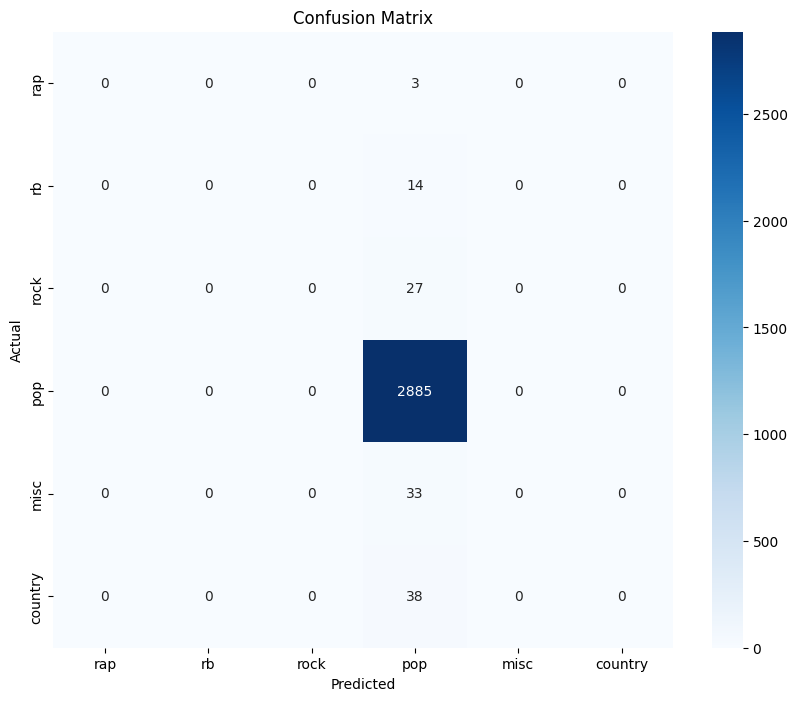
This confusion matrix for the Multinomial Naive Bayes Model provides insights into the model’s performance across different genres. The imbalance suggests that the model may be biased towards predicting the ‘pop’ genre. This is possibly due to an imbalance in the dataset or features that strongly correlate with the ‘pop’ genre, or potentially due to the inherent characteristics of the dataset. In future steps we seek to improve the model and re-evaluate the confusion matrix.
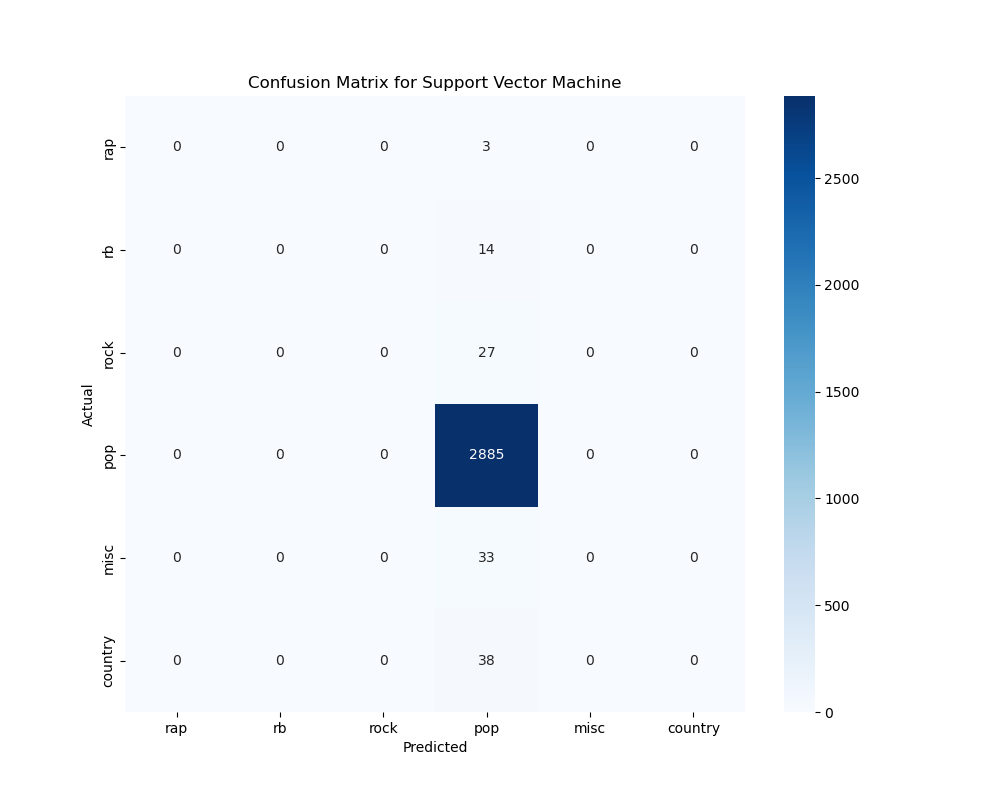
This is the confusion matrix for the Support Vector Machine Model we trained. It can be seen that this model is also biased towards predicting every genre as pop. This is most likely due to our dataset having a wider subset of pop songs compared to other genres so the model has not been trained well enough with the other genres.

This is the confusion matrix for the Decision Tree classifier that was implemented for our dataset. It is shown that this model is accurately predicting all of the genres at least once. Once again, the model is correctly predicting pop genres the most due to the dataset having a larger subset of pop songs.
Quantitative Metrics
We used 4 quantitative metrics to test our ML models: accuracy, precision, recall and F1 score. Our goal for all of the metrics would be to maximize the value as close to 1 as possible. We received the following scores using the Scikit-Learn, a ML library that we can use to calculate these performance metrics. For Multionomial Naive Bayes, accuracy was 0.962, precision was 0.9631, recall was 0.962, and F1 score was 0.943. For Decision Tree Classifier, accuracy was 0.94, precision was 0.937, recall was 0.94, and F1-score was 0.938. For Support Vector Machine, accuracy was 0.962, precision was 0.963, recall was 0.962, and F1-score was 0.943.
Discussion
The ML models we chose have many advantages and drawbacks. For example, Multinomial Naive Bayes is well-suited for classification tasks and has been applied to genre classification based on song lyrics. It is efficient and simple to implement with fast training and prediction times. It can also high-dimension data from text-based datasets. However, it relies on bag-of-words representation and performs poorly with highly imbalanced datasets. Support Vector Machine is effective in high-dimensional spaces, is versatile, and is robust to overfitting. However, it can lead to misclassification if there are noisy classes and is more susceptible to overfitting. Decision Tree Classifier is suitable at generating insights into feature importance and can handle categorial data. However, it has a greedy nature and is not very robust. All of these factors contribute to how our models performed which can be seen based on the scoring metrics and the visualizations presented above. From our results, we can analyze the performance metrics. All 3 models have high scores for accuracy, precision, recall, and F-1 score showing us that our models are performing well when classifying song lyrics into genres. We want to see scores above .8 for accuracy and scores above .7 for precision, recall, and F1 score. However, all scores are above 0.9, which shows a positive result for our model’s performance. There are several reasons why we have well performing models. To begin with, the data has been preprocessed by encoding each of the genres into numbers, feature extraction, and splitting our dataset into a train and a test set. This made sure the data is in an optimal state to be utilized with the models. We also made sure to choose models that work well for our specific project scenario. Using Multinomial Naive Bayes, Support Vector Machine, and Decision Tree Classification are good choices for working with the dataset we chose and classification in general. Our code has also been implemented correctly leading us to accurate performance. However, our confusion matrices show biases towards ‘pop’ in all of our models, although Decision Tree Classification is not as biased compared to the other two models. While all three models are good at handling numerical data, DTC is better at handling noisy data and focusing on the most relevant features to use for classification. This is likely why DTC is performing better with our data compared to the other two models based on their confusion matrices.
For the next steps of the project, there are ways to improve performance of the model. In general, a larger data set with larger subsets of other genres (such as rap, rock, country, etc.) can be introduced to train the models with a variety of data points. This will help the models be familiar with a wider set of data points. In addition, it might be beneficial to preprocess the datasets even more, highlighting only the most relevant features to train our models with. This might increase accuracy later on when newer data sets are fed into the model and when the most relevant features are chosen. We can also consider adding more models to see how the accuracy is with the data. For example, we could add random forests, neural networks or gradient boosting machines. We can also collaborate with industry professionals to see how to improve the algorithms to perform in a more optimal way. Conducting market research will help us optimize our product to what would be most useful for consumers.
References
[1] “1.4. Support Vector Machines — scikit-learn 0.22.1 documentation,” scikit-learn.org. https://scikit-learn.org/stable/modules/svm.html#classification
[2] “1.9. Naive Bayes — scikit-learn 0.23.2 documentation,” scikit-learn.org. https://scikit-learn.org/stable/modules/naive_bayes.html#multinomial-naive-bayes
[3] scikit-learn, “sklearn.model_selection.train_test_split — scikit-learn 0.20.3 documentation,” Scikit-learn.org, 2018. https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
[4] “3.3. Metrics and scoring: quantifying the quality of predictions — scikit-learn 0.24.1 documentation,” scikit-learn.org. https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics
[5] “sklearn.metrics.accuracy_score — scikit-learn 0.24.1 documentation,” scikit-learn.org. https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
[6] “sklearn.metrics.precision_score — scikit-learn 0.24.1 documentation,” scikit-learn.org. https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html#sklearn.metrics.precision_score
[7] “sklearn.metrics.recall_score,” scikit-learn. https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score
[8] “sklearn.metrics.f1_score,” scikit-learn. https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score
[9] Li, T., Ogihara, M., & Tzanetakis, G. (Eds.). (2011). Music data mining. CRC Press.
[10] Boonyanit, Anna & Dahl, Andrea. Music Genre Classification using Song Lyrics. Stanford University.
[11] Nayak, Nikhil, Apr 8, 2022, “Genius Song Lyrics”, Kaggle. [Online]. Available: https://www.kaggle.com/datasets/carlosgdcj/genius-song-lyrics-with-language-information
Gantt Chart
Contribution Table